 |
Интернет, в котором можно найти почти любую информацию, очень похож на огромную библиотеку, которая каждый день становится больше и больше. Под массой новых поступлений тонет информация, которая, скорее всего, рано или поздно кому-нибудь точно понадобится. Изменение интернет-сайта, вызванное какими-либо причинами, может сделать недоступной информацию, которая очень необходима пользователю в данный момент. Существует несколько возможностей добыть информацию, которая была доступна, а потом пропала.
На самом деле все возможности сводятся к одному и тому же: информацию надо найти там, где по какой-то причине она осталась в виде архива, кеша или в другой форме.
Самый первый способ, которым следует воспользоваться, заключается в том, чтобы поискать нужный вам документ в кеше популярных поисковых сервисов. Называется такая возможность у всех по-разному, но так или иначе присутствует у всех популярных поисковых систем.
- «Сохраненная копия» на /redir.php?url=yandex.ru%2F%3C%2Fa%3E%26nbsp%3B%26mdash%3B под каждым результатом, который выдает поиск, размещается ссылка на копию сайта, которая была сохранена в ходе индексации. Таким образом, довольно часто можно открыть даже те страницы, которые уже некоторое время не существуют, но до сих пор находятся в индексе. Сохраненная копия документа будет представлена в том виде, в котором сайт был в момент индексации. Это довольно удобно тем, что позволяет просматривать не только текстовое содержимое искомой страницы, но и графические материалы сайта.
- «Восстановить текст» на /redir.php?url=rambler.ru%2F%3C%2Fa%3E%26nbsp%3B%26mdash%3B принцип и объем предоставленной информации приблизительно такие же, как и у всех аналогов. Серьезным отличием от некоторых аналогов является то, что эта система сохраняет уже обработанную страницу, которая обычно уже очищена от части HTML-форматирования. Полностью теряются вся графика и другие элементы дизайна. Это не очень удобно в тех случаях, когда нужно восстановить содержимое сайта полностью, но текстовое наполнение страницы не теряется и остается вполне пригодным для чтения и использования.
- Cached на /redir.php?url=google.com%2F%3C%2Fa%3E%26nbsp%3B%26mdash%3B сохраняет полностью все содержимое страницы, не изменяя его. Кроме того, присутствует ссылка на эту же страницу, но очищенную от HTML-форматирования и без графики. Кроме того, отображаются дата и время, когда страница была занесена в индекс. Такая информация может стать довольно полезной, если разыскивается совершенно конкретное содержимое страницы, которое было в какой-то момент, а потом было перемещено или удалено.
Популярные поисковые сервисы хранят в кеше страницы, которые могут быть уже недоступны
Так как поисковые сервисы непосредственно показывают кешированную страницу, все они предваряют показ предупреждением о том, что не несут ответственность за содержимое данной страницы.
Следует отметить, что поисковые сервисы специально не занимаются сбором и учетом устаревших страниц. Данная функция предоставляется параллельно с основной их деятельностью, так или иначе данная информация сохраняется в индекс, и поисковые системы всего лишь дают доступ к тому, что и так сохраняется. Они не занимаются каталогизацией или каким-либо учетом страниц. В кеше поисковых систем нельзя найти версию сайта старше, чем версия, которая в последний раз была занесена в индекс.
К счастью, поисковые сервисы — не единственное место, в котором можно искать информацию, которая была на сайте в какой-то момент, а потом пропала. Сервисы, которые профессионально занимаются хранением различной информации, называются интернет-архивами. Одним из крупнейших представителей данной области является The Internet Archive ("Интернет-архив"). Данный сайт поддерживается некоммерческой организацией, которая ставит своей целью поддержку онлайн-библиотеки и архива веб- и мультимедиаресурсов. Данный архив бесплатно предоставляет огромное количество разнообразной информации, такой как сохраненные в различное время копии различных интернет-сайтов, книги, видеозаписи и аудиозаписи. Кроме того, архив является членом организации, которая объединяет библиотеки в США, что позволяет хранить в архиве материалы, которые ранее были доступны только посетителям обычных библиотек. Из некоторых данных следует, что многие крупнейшие библиотеки мира в настоящий момент уже хранят меньшее количество материалов, чем "Интернет-архив".
"Интернет-архив" хранит больше материалов, чем любая библиотека мира
"Интернет-архив" хранит огромное количество аудио-, видео- и текстовых материалов, поиск по которым позволяет получать доступ к огромному количеству материалов, которые ранее были доступны только пользователям специализированных библиотек. Однако одним из важных сервисов, которые предоставляет данный архив, является сервис Wayback Machine (дословно — «машина, возвращающая назад»). Он представляет собой огромный и постоянно пополняющийся архив различных интернет-страниц, который позволяет пользователю искать сохраненную в конкретный момент страницу. Разработчики заявляют, что ежемесячно размер их базы сохраненных материалов увеличивается на 20 терабайт (два в сороковой степени байт), а суммарный размер архива уже почти достиг двух петабайт (два в пятидесятой степени байт).
Ежемесячно количество сохраненных материалов увеличивается на 20 терабайт
Простой поиск в архиве сохраненных сайтов выдает ссылки на все сохраненные копии запрашиваемой страницы. Анализируя результаты различных запросов, становится очевидно, что с каждым годом сервис наращивает обороты: сохраненных копий из года в год становится все больше и больше. К примеру, по запросу /redir.php?url=freebsd.org%3C%2Fa%3E всего выдано 1372 результата, из которых только 6 приходится на 1996 год, когда этот сайт был впервые занесен в архив. В 1997 году результатов было немногим больше — всего 10, а в 1998 — уже 15. Далее количество многократно увеличивается из года в год, достигая максимума в 2006 году (за исключением 2002-2003 годов, в которые по какой-то причине было относительно небольшое количество сохраненных копий).
Довольно полезным является то, что знаком "*" отмечены копии страниц, которые были обновлены по сравнению с предыдущей копией.
Как показывает результат, во многих случаях архив хранит по несколько копий сайта в одном и том же его состоянии. В результатах поиска /redir.php?url=freebsd.org%3C%2Fa%3E встречается до 10 страниц подряд, которые отмечены как неизменившиеся со времени последнего архивирования.
Присутствует специальная возможность указать некоторые параметры поиска, такие как:
- дата, с которой начинать поиск сохраненных страниц. Имеется в виду день, в который сделана самая ранняя копия, которая должна войти в результаты поиска;
- день, который должен считаться последним днем для поиска;
- возможность сравнения двух результатов поиска. Причем результаты сравнения показываются настолько удачно (хотя и не без некоторых сбоев на отдельных страницах), что сравнение становится действительно удобной и полезной функцией для тех, кто заинтересован в изучении разницы между двумя версиями страницы. Причем каждую из сравниваемых копий можно оперативно посмотреть по специальной ссылке в шапке страницы сравнения;
- конвертация желаемой копии страницы в PDF-формат. В настоящий момент пока бета-версия сервиса;
- тип файлов, которые нужны в результате. Сейчас это один из следующих типов: All Types, Images, Audio, Video, Binary, Text и PDF. Причем результат поиска по любому формату, кроме All Types, выдает только конкретные ссылки на файлы запрашиваемого формата;
- поиск наиболее подходящей страницы или всех страниц, которые удовлетворяют запросу.
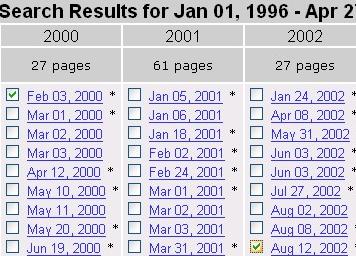 |
| Выбор сохраненных версий страницы для сравнения |
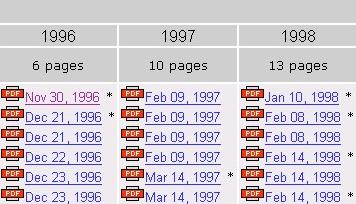 |
| Сохранение архивной копии страницы в формате PDF |
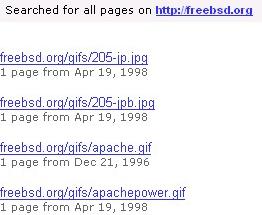 |
| Результаты поиска графических файлов в архивных копиях сайта /redir.php?url=freebsd.org%3C%2Fa%3E%3C%2Ftd%3E%3C%2Ftr%3E |
Отдельного внимания заслуживает то, что сервис старается предоставлять максимальное удобство в использовании тем, кто готов запомнить несколько довольно простых способов написать запрос сразу в строке своего браузера. К примеру, для того, чтобы посмотреть самую последюю сохраненную копию сайта /redir.php?url=www.opennet.ru%3C%2Fa%3E%2C надо набрать ссылку /redir.php?url=web.archive.org%2Fhttp%3A%2F%2Fwww.opennet.ru%3C%2Fa%3E. После чего система обработает запрос и перенаправит на страницу с последней копией — /redir.php?url=web.archive.org%2Fweb%2F20060428035504%2Fwww.opennet.ru%2F%3C%2Fa%3E. В данном случае фрагмент адреса «20060428035504» указывает на момент создания последней копии в архиве. Точно таким же образом можно получить архивную копию страницы в конкретный день, для этого достаточно указать дату в таком же формате, но следует учитывать, что необязательно есть копия сайта именно в этот день. Если же копии в указанный день нет, то система перенаправляет на страницу с ближайшей датой сохранения.
"Интернет-архив" — это удобный поиск, возможность сравнения различных копий страницы и мгновенной конвертации в PDF
Для того чтобы различать поиск конкретной страницы сайта и поиск копии всего сайта, нужно использовать символ "*". Этот символ должен быть добавлен до адреса и в конец адреса в том случае, если желаемый результат является сайтом, а не конкретной страницей. Например, для поиска конкретной страницы /redir.php?url=opennet.ru%2F%3C%2Fa%3E в строке адреса браузера надо ввести /redir.php?url=web.archive.org%2Fhttp%3A%2F%2Fwww.opennet.ru%3C%2Fa%3E%2C но для поиска всех страниц данного сайта надо добавить "*", то есть /redir.php?url=web.archive.org%2F%2Ahttp%3A%2F%2Fwww.opennet.ru%2A%3C%2Fa%3E или target="_blank" href="/redir.php?url=web.archive.org/200502*/http://www.opennet.ru*">/redir.php?url=web.archive.org%2F200502%2A%2Fhttp%3A%2F%2Fwww.opennet.ru%2A%3C%2Fa%3E.
Что касается работы самого сервиса по архивированию информации, то тут все стандартно и ожидаемо — с самого начала своего существования в 1996 году архив работает приблизительно на тех же принципах: при работе учитывается информация из robots.txt, если сервис не знает о конкретном сайте (в том числе если на сайт нет ссылок на других сайтах), то и архивироваться он не будет. Определенные проблемы в сохранении страниц возникают в тех случаях, когда на страницах используются элементы Java Script, особенно если они генерируют ссылки без полного имени страницы. Кроме того, если скрипты или графика должны быть взяты со стороннего сервера, то это тоже вызывает проблемы при архивировании.
Таким образом, сервис Wayback Machine предоставляет отличные возможности для поиска информации, которая могла быть на сайте еще год назад, но сейчас там отсутствует. Несмотря на то что в настоящий момент искать можно только по имени страницы или сайта, сервис все равно представляет интерес для тех, кто интересуется историей развития определенных интернет-ресурсов. Кроме того, разработчики "Интернет-архива" постоянно ведут работу над расширением функций поиска и добавлением возможности полноценного поиска по всему тексту. Уже в настоящий момент архив является самым крупным и самым динамично развивающимся хранилищем данных в Интернете, что позволяет надеяться на то, что он будет полезен при решении самых различных задач.
Ссылки по теме
Статья получена: hostinfo.ru










 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить




