 |
Олимпийский девиз «Быстрее, выше, сильнее» постепенно начинает распространяться не только на спорт, но и на другие сферы жизни, и Веб не исключение: требования к скорости (читай — комфортности) работы постоянно растут. В этой статье мы рассмотрим, как ускорить обработку файлов обменных типов (CSV, XML) за счет использования базы данных.
Для начала обратим свои взоры на формат CSV.
CSV-файл (Comma Separated Values — «значения, разделенные запятыми») представляет собой обычный текстовый файл, содержащий таблицу данных. В первой строке такого файла обычно через запятую указаны имена столбцов, а во всех последующих строках — их значения в том же порядке.
Так, например, при экспорте адресной книги из почтовой программы The Bat! в CSV-файл он может выглядеть так:
С помощью CSV-файла удобно обмениваться табличными данными
ФИО, E-mail, псевдоним
Иванов И. И., i@server.ua, Вано
Петров П. П., p@server.ua, Петруччо
Сидоров С. С., s@server.ua, Сидор
Самый большой плюс, снискавший популярность этому формату, — простота. Многие языки программирования имеют встроенные функции для работы с ним (например, fputcsv() и fgetcsv() в PHP), а в отсутствие оных программисту не составит труда написать функцию, разбирающую файл на составляюшие. Поэтому если наша задача — импортировать данные из CSV-файла в базу данных, то алгоритм будет таков:
- считать очередную строку;
- сформировать массив значений;
- выполнить INSERT-запрос к базе с этими значениями.
Этот метод отлично работает, если файл данных небольшой. Но реальный мир предъявляет свои требования — и как поведет себя такая функция с файлом размером в несколько десятков мегабайт?
Поскольку вышеназванные функции обрабатывают файл построчно, то загрузка данных в базу происходит очень медленно: автор этих строк так ни разу и не дождался, когда же на PHP обработается тестовый файл размером 40 Мб.
Как решение можно использовать группировку INSERT-запросов: один большой INSERT вместо множества маленьких, MySQL это позволяет. Но построчная обработка все равно занимает львиную долю времени.
В таком случае лучше использовать технологию, которая называется bulk insert, — загрузка файла целиком, благо, как оказалось, MySQL предоставляет такую возможность: существует специальный запрос LOAD DATA INFILE, позволяющий оперативно загружать данные CSV-файла в таблицу базы данных, ведь они очень похожи по структуре. Этот запрос позволяет определить следующие параметры загрузки:
- имя загружаемого файла;
- опции полей и строк: какие символы используются для их разделения и экранирования;
- что делать с повторяющимися строками — пропускать или перезаписывать;
- пропуск первых N строк. Как правило, пропускают первую строку, содержащую заголовок;
- задать определенные значения нужным полям.
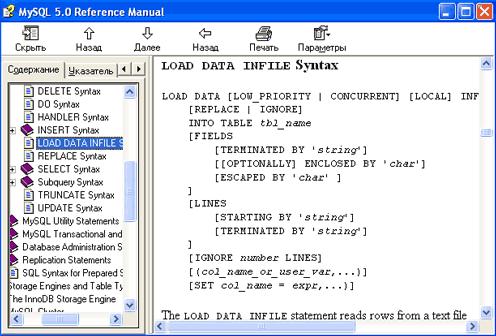 |
| Читайте инструкцию, там все есть |
Дополнительную информацию по более тонкой настройке можно найти в документации, впрочем, не слишком изобилующей примерами.
Поразительно, но упомянутый
Кстати, в других серверах БД тоже есть похожий инструментарий. Например, в MS SQL можно воспользоваться консольной программой bcp. Тем не менее выполнение SQL-запроса предпочтительней, поскольку обеспечивает кросс-платформенность, в то время как дополнительное ПО обычно жестко привязано к определенной операционной системе.
Таким образом, загрузка файла с:\1.csv может быть выполнена следующим запросом:
LOAD DATA INFILE 'с:\\1.csv'
REPLACE
INTO TABLE table1
FIELDS
TERMINATED BY ','
LINES
TERMINATED BY '\r\n'
IGNORE 1 LINES
Указание кодировки просто необходимо для обработки интернациональных данных
Данные бывают разные, и часто нужно указать, в какой кодировке они созданы. К сожалению, запрос LOAD DATA INFILE не позволяет указать это явно, поэтому перед его выполнением нужно выставить нужную кодировку в серверной переменной character_set_database — согласно документации, именно она отвечает за разбор данных. Так, например, если файл был создан в Windows и содержит русский текст (кодировка Windows 1251), нужно запустить такую SQL-команду:
SET SESSION character_set_database = cp1251;
Как видно из этого примера, MySQL имеет собственный список имен кодировочных таблиц, не совпадающий со ставшими привычными обозначениями, используемыми в веб-страничках. Чтобы получить список доступных на MySQL-сервере кодировок (а этот список варьируется от одного сервера к другому), выполните следующий запрос:
SHOW CHARACTER SET;
Для импорта CSV-файлов в MySQL-базу через PHP можно использовать готовый класс Quick CSV import.
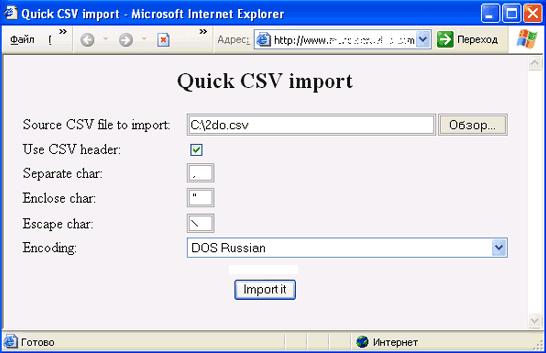 |
| Пример работы класса Quick CSV import |
Теперь рассмотрим работу с XML (eXtensible Markup Language — «расширяемый язык разметки»).
Этот текстовый теговый формат весьма популярен, поскольку в унифицированной форме представляет данные любого формата, что делает его универсальным средством для обмена данными, но не их хранения, и потому его унифицированность наносит непоправимый ущерб удобству доступа к данным. XML в его стандратном обличье никогда не сравнится в удобстве работы с данными, скажем, с SQL.
Предыдущий пример CSV-файла, перенесенный в XML, будет выглядеть так:
<?xml version="1.0"?>
<book>
<entry>
<FIO>Иванов И. И.</FIO>
<E-mail>i@server.ua</E-mail>
<Nick>Вано</Nick>
</entry>
<entry>
<FIO>Петров П. П.</FIO>
<E-mail>p@server.ua</E-mail>
<Nick>Петруччо</Nick>
</entry>
<entry>
<FIO>Сидоров С. С.</FIO>
<E-mail>s@server.ua</E-mail>
<Nick>Сидор</Nick>
</entry>
</book>
Для переноса данных из XML-файла в базу данных изначально использовался такой алгоритм:
- считать весь файл в строку;
- преобразовать XML в PHP-массив;
- выполнить серию INSERT-запросов;
Этот метод, как и следовало ожидать, оказался, во-первых, очень медленным, во-вторых, требующим много памяти. По умолчанию PHP владеет 8 мегабайтами оперативной памяти, и попытки быстро работать с массивами, преобразованными из многомегабайтных прайс-листов в XML-формате, — жалкое зрелище. Другой замедляющий момент — обилие запросов к базе. Даже если веб-сервер и БД стоят на одной машине, что должно снижать накладные расходы, количество запросов будет так велико, что работа затянется надолго.
Поэтому имеет смысл опробовать такой алгоритм:
- считать весь файл в строку;
- преобразовать XML в PHP-массив;
- сохранить весь массив в CSV-файл;
- использовать быструю загрузку CSV в БД.
Несмотря на то что в этом алгоритме присутствует строковая переменная, содержащая данные всего файла, что должно было бы негативно сказаться на скорости, данный алгоритм в разы быстрее предыдущего. В принципе можно попробовать пойти дальше и ускорить этот процесс еще и тем, что сохранять в файл блоки данных, скажем, при достижении N строк или при пересечении массивом предела в объеме, однако и так алгоритм дает существенный прирост производительности.
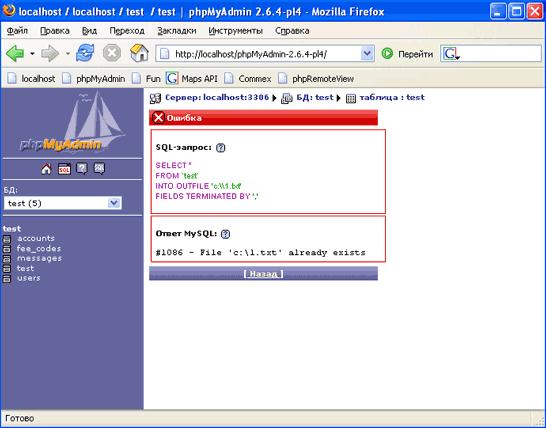 |
| Пример ошибки, возникающей, если файл уже существует |
По поводу упомянутого преобразования XML в массив: множество примеров можно найти на сайте php.net. Алгоритм этот нетривиальный, поэтому следует поэкспериментировать и выбрать подходящий.
Пару слов стоит сказать о быстром экспорте данных в CSV — он намного проще. Опять же, не стоит заниматься построчной обработкой — производительнее и проще использовать до боли знакомый SELECT, у которого есть поддержка вывода результатов во внешний файл.
Единственное ограничение — файл не должен существовать; это сделано во избежание несчастных случаев на производстве вроде затертых системных файлов.
Данный запрос использует те же настройки, что и запрос LOAD DATA INFILE.
Простейший SQL-запрос для экспорта будет выглядеть так:
SELECT * FROM 'test'
INTO OUTFILE 'c:\\1.txt'
FIELDS TERMINATED BY ','
Таким образом, можно сделать вывод, что каждый инструмент хорош для решения своего определенного круга задач и, если с новой задачей он не справляется, следует поискать что-то более подходящее.
Ссылки по теме
- LOAD DATA INFILE Syntax
- Class: Quick CSV import
- ua_mysql
- PHP-функция fgetcsv()
- Преобразование XML в структуру
Статья получена: hostinfo.ru










 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить




