 |
Поиск — обычное состояние любого компьютерного пользователя. Время от времени нужно найти файл на жестком диске или съемном носителе. Еще чаще требуется отыскать слово или фразу в пространном текстовом документе. Вебмастер постоянно разыскивает те или иные фрагменты HTML-кода в своих страницах. Для программиста и разработчика веб-приложений задача поиска еще более актуальна.
Ведь в общем случае, прежде чем что-либо сделать с неким массивом данных, его нужно правильно выделить из общего потока, иначе говоря, найти.
При этом даже такая простейшая операция, как поиск файла по его имени, бывает связана с некоторыми трудностями. Зачастую пользователю не известно точное название файла или его расширение, поэтому приходится прибегать к различного рода шаблонам, или маскам. Например, для обнаружения всех текстовых документов в строку поиска вводится маска *.txt. Вообще, любой поиск подразумевает применение некоего шаблона, сложность которого зависит от стоящей перед пользователем задачи.
А задачи частенько возникают совсем нетривиальные, особенно в случае разработки веб-приложений. Причем обычно нужно не только найти данные, но и совершить с ними некие действия, совершить замену. Скажем, требуется средствами языка программирования найти в тексте все слова, набранные прописными буквами, и перевести их в нижний регистр. Иногда нужно выделить отдельные слова из текстового фрагмента, извлечь несколько строк из файла, «выкусить» из HTML-документа все теги и оставить только содержательную текстовую часть. Отдельная тема — «зачистка» HTML-кода от излишних тегов, проставленных каким-нибудь редактором (например, Microsoft Word) при сохранении форматированного текста в виде веб-страницы. Очень часто приходится проверять корректность данных, введенных посетителем сайта в HTML-форму — например, адрес сайта или электронной почты. И в этом случае требуется сравнить введенные пользователем данные с некоторым шаблоном. Одним словом, существует огромное количество задач, требующих составления сложных шаблонов поиска и замены.
В общем же случае шаблоны применяются для:
- обнаружения в тексте или программном коде данных, соответствующих шаблону,
- выдачи пользователю данных, соответствующих шаблону,
- замены одного фрагмента текста, соответствующего определенному шаблону, другим фрагментом, соответствующим иному шаблону.
О популярности регулярных выражений Perl говорит тот факт, что для языков C/C++ разработана библиотека PCRE (Perl Compatible Regular Expression), а Regex из Microsoft Visual Studio.Net полностью совместима с PerlРазличные языки программирования имеют свои средства составления поисковых шаблонов. Причем, как правило, эти средства вынесены в отдельные библиотеки, модули или объекты. Наиболее «продвинут» в этом плане язык Perl. Встроенные в него регулярные выражения (Perl Regular Expressions) — настолько мощный инструмент, что его применяют даже в приложениях, напрямую не связанных с программированием. Другими словами, регулярные выражения Perl стали неким стандартом составления шаблонов поиска и замены. Полное описание всех возможностей и нюансов применения этого механизма могло бы стать темой серии статей или даже отдельной книги. Здесь же мы ограничимся изложением основных принципов применения регулярных выражений для составления шаблонов поиска. Для простоты восприятия будем «решать» гипотетические поисковые задачи.
Понятно, что когда точно известен объект поиска, шаблон будет совпадать с этим объектом. Например, если требуется обнаружить в тексте слово музыка, то шаблоном поиска станет само слово музыка. Задача усложняется, если нужно обнаружить это же существительное, но во всех словоформах. Здесь без применения так называемых метасимволов в регулярном выражении не обойтись. В данном конкретном случае можно применить метасимвол «точка» (.), который соответствует любому символу. То есть регулярное выражение музык. станет шаблоном для данного поиска, а его результатом будут слова музыка, музыки, музыке, музыку и так далее.
Квадратные скобки в регулярном выражении означают, что в них заключен некий набор одиночных символов или диапазон символов, соответствующий определенному условию. Например, [0-9] означает любую цифруСтоп! А как же творительный падеж, музыкой? С помощью приведенного выше регулярного выражения эту словоформу мы в тексте не обнаружим, вернее, результатом поиска станет «обрубок» музыко. Если же использовать два метасимвола «точка» подряд (музык..), то в результат поиска попадут не только слова, но и пробелы, следующие за ними: музыка , музыки , и так далее. Необходимо усложнить наш шаблон, вместо «точки» применить другой метасимвол, точнее, перечень или диапазон [а-я], который означает любую прописную кириллическую букву. А для пущей точности укажем, что после «постоянной» части слова музык таких символов должно быть не меньше одного, но не больше двух: музык[а-я]{1,2}. Вот теперь шаблон точен, в результате поиска по нему мы получим слово музыка во всех падежах.
А что получится, если при поиске встретится прилагательное музыкальный? Ничего хорошего, поскольку шаблон выделит из него музыкал. Значит, нам необходимо добавить в шаблон условие, что после «постоянной» части слова музык и после одного или двух символов, определяемых диапазоном [а-я] слово должно заканчиваться. Для этого используется еще один метасимвол, \b — граница слова. Таким образом, наш шаблон теперь выглядит так: музык[а-я]{1,2}\b.
Задумаемся над следующим моментом. Искомое слово может встретиться в начале предложения. В таком случае оно будет начинаться с заглавной буквы, и наше регулярное выражение его не обнаружит. То есть необходимо предусмотреть два варианта начала слова. Делается это просто — с помощью метасимвола выбора вариантов, | и обычных круглых скобок. В нашем случае они будут использованы следующим образом:
А как быть, если нам не нужно ограничиваться поиском существительных, а необходимо выбрать из текста и прилагательное музыкальный, во всех словоформах? Сразу же в голову приходит мысль, что шаблон должен быть несколько сокращен:
Но что мы все о музыке, да о музыке? Сделаем нашу «задачу» более прикладной. Допустим, в нашем гипотетическом тексте допущена ошибка: некоторые предложения начинаются не с заглавной буквы. Как обнаружить такие несуразности? Первым делом найдем все начала предложений. Мы должны учесть следующие варианты:
- Предложение начинает какой-либо абзац текста, то есть его начало совпадает с началом строки.
- Предложение находится внутри абзаца, то есть перед его началом следует знак препинания (точка, восклицательный знак или знак вопроса) и пробел.
Кроме того, нужно учитывать, что перед первой буквой предложений, начинающих абзац, могут находиться несколько пробелов или символ табуляции для обозначения абзацного отступа (красной строки). Но и это еще не все. Если в тексте встречаются диалоги, то первым символом абзаца может стать тире или дефис. Если в тексте встречается прямая речь или цитаты, то началом предложения или абзаца могут стать различные кавычки.
Внешние квадратные скобки [] в приведенном здесь шаблоне вновь определяют перечень (диапазон), то есть некий набор символов. В данном случае таким набором стали все буквы нижнего регистра, описанные классом модуля POSIX [:lower:]Выяснив все варианты начала предложений, опишем их в синтаксисе регулярных выражений и найдем все предложения, начинающиеся с маленькой буквы. Начнем с проверки предложения, начинающего какой-либо абзац:
- ^ — метасимвол начала строки,
- \s — метасимвол, обозначающий любой «пробельный» элемент, который может встречаться в начале абзацев,
- * — метасимвол-повторитель, который позволяет нам обнаружить любое количество (ноль или более) символов, соответствующих предшествующему метасимволу (в нашем случае — \s),
- [:lover:] — класс символов модуля POSIX, включающий все буквы в нижнем регистре.
Теперь добавим условие проверки остальных предложений, находящихся внутри абзацев нашего текста. Сделаем это при помощи уже описанного нами выше метасимвола выбора вариантов (|). Наш шаблон изменится следующим образом:
Шестнадцатеричные коды тех или иных символов можно узнать, например, в служебной утилите «Таблица символов», входящей в состав операционной системы Windows (см. иллюстрацию)Для окончательного решения задачи разберемся с диалогами и цитатами. В случае диалогов после начала строки может находиться символ дефиса, а также длинное или короткое тире. Следовательно, нам необходимо добавить в шаблон к символу начала строки ^ необязательный (ведь не все абзацы нашего текста — диалоги) перечень этих знаков препинания. Этот перечень будет выглядеть следующим образом: [-\x96\x97]*, где дефис обозначает собственно дефис, а \x96 и \x97 — шестнадцатеричные коды короткого и длинного тире. Звездочка *, как вы понимаете, обозначает необязательность присутствия всех знаков из перечня в начале абзаца.
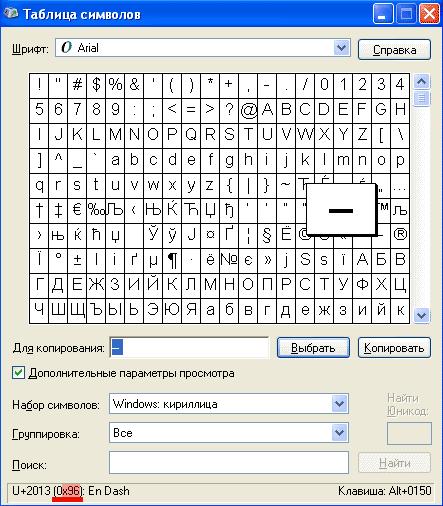 |
| Красным цветом выделен шестнадцатеричный код короткого тире — x96 |
Наконец, предусмотрим в нашем шаблоне возможность присутствия разного рода кавычек в начале каждого предложения. Шестнадцатеричные коды кавычек выглядят следующим образом:
- \x22 — для обычных кавычек ",
- \xAB — для открывающих типографских кавычек «,
- \x93 — для открывающих «европейских» кавычек “,
В конечном итоге, наш шаблон разросся и превратился в довольно длинную строку:
В заключение отмечу, что регулярные выражения Perl в большинстве случаев позволяют решать одну и ту же задачу разными способами. Все приведенные здесь примеры задач и их решения не отличаются особой изящностью, поскольку призваны всего лишь продемонстрировать основные принципы применения регулярных выражений. Предлагаю читателям в комментариях к этой статье ставить свои задачи или приводить собственные варианты решений, использовать другие метасимволы и способы построения поисковых шаблонов. В результате мы сможем более глубоко вникнуть в увлекательный процесс автоматизированного поиска по шаблону.
Ссылки по теме
- Спецификация регулярных выражений Perl
Статья получена: hostinfo.ru










 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить

