Бурная волна доткомов конца
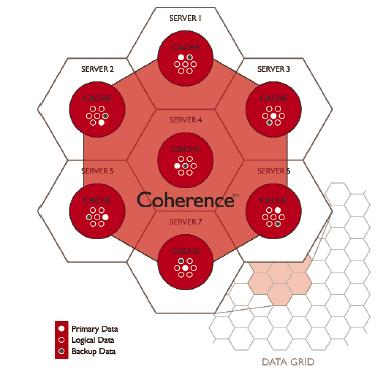 |
| Рис. 1.
Схема кластеров |
Coherence ориентирован на работу с Java-приложениями и серверами. В частности, это BEA WebLogic, IBM WebSphere, Sun JSAS, Jacarta Tomcat, JBoss и ряд других как на платформе PC, так и на промышленных серверах SPARC- и RISC-архитектуры. Таким образом, рассматриваемый продукт может использоваться для весьма широкого спектра популярных платформ построения и поддержки веб-решений. Даже короткий взгляд на перечень платформ дает основание заключить, что балансировочное решение может применяться для следующих видов решений:
- сайты, предоставляющие сервисы доступа к большим объемам данных и с большим количеством посетителей или пиковыми нагрузками;
- онлайн-сервисы, предоставляемые банками, службами аренды и т. п.
Балансировка нагрузки на серверы данных
Управление данными
Рассмотрим организацию масштабируемого производительного управления данными, предлагаемую Coherence. Графически схема распределения данных показана на рис. 1. Суть используемой схемы состоит в организации многоуровневого кеша данных, разделяемого на три логических сегмента: первичные данные, логические данные (или Views, выборки) и архивные данные (бэкапы). Сами данные, как и кеши, могут размещаться на отдельных серверах или в кластерах данных (см. рис. 1). При этом производится периодическая или событийная синхронизация данных в кеше с исходным хранилищем, что позволяет предоставлять пользователю актуализированную информацию. Сразу возникает вопрос: а как такое регулярное обновление сказывается на производительности системы? Coherence использует подход, связанный с отслеживанием изменений. Выглядит это примерно следующим образом:
- На сервере БД при инсталляции приложения устанавливаются служебные таблицы, триггеры и хранимые процедуры. Сам Coherence устанавливается в слое веб-серверов.
- По установленному при развертывании решения протоколу (правилам) направляются запросы на наличие изменений. В кеш данных подкачиваются только измененные данные.
- В кластере кеша данных накапливается статистика обращений как по веб, так и по данным. На основании статистики производится перераспределение наборов данных в кеше. Coherence поддерживает пять типов кешей:
- локальный — не использует кластеры;
- реплицируемый — все данные реплицируются на каждый кеш-сервер. Обеспечивает наибольшую надежность хранения данных при относительно невысокой производительности;
- оптимистический — данные реплицируются на каждый кеш-сервер, однако конкурентность потоков не отслеживается. Данный способ обеспечивает наибольшую производительность;
- каждый сегмент данных распределяется между различными серверами кластера. Целостность данных обеспечивается специальными процедурами. Этот вид кеширования обеспечивает минимальный объем памяти и серверных ресурсов;
- гибридные виды кешей — NearCache и VersionedNearCache.
Управление данными в кеше непосредственно в приложении Coherence позволяет распределять их в зависимости от поступающих запросов, их частоты и интенсивности и таким образом повысить масштабируемость решения. Например, для системы интернет-банкинга не потребуется увеличивать количество обслуживающих серверов или, напротив, содержать избыточные серверы для обслуживания пиковой нагрузки.
HTTP-сессии пользователей
Управление сессиями пользователя
Coherence использует протокол TCMP — специализированный протокол обмена данными в кластере, основанный на комбинации протоколов UDP/IP и TCP/IP. UDP/IP используется для передачи данных, в том числе при их распределении по кластерам. TCP/IP в основном используется для выявления смерти сессии, то есть установления факта разрыва соединения или окончания сессии пользователем. При определенной конфигурации сети протокол TCMP может обеспечивать связь типа point-to-point.
Использование такого нестандартного протокола позволяет обеспечивать управление сессиями огромного числа пользователей (до нескольких десятков тысяч) при больших объемах данных. Управление HTTP-сессиями заключается в выполнении следующих основных функций:
- кластеризация данных сессий пользователей;
- восстановление данных сессий после разрыва и успешной аутентификации;
- дополнительная опция — веб-сервис, обеспечивающий поддержку пользовательских сессий и целостность данных между распределенными удаленными веб-серверами.
Режим кластеризации пользовательских сессий поддерживает возможность настройки атрибутов, разделяющих данные пользовательских сессий на требующие и не требующие восстановления при разрыве соединения или иной потере сессии.
Coherence API
API
Для настройки многочисленных возможностей сервера Coherence и их адаптации к требованиям конечных решений разработчиками предоставлен достаточно богатый интерфейс — Coherence API, который является единым как для слоя данных, так и для логического уровня. Слой управления данными представлен двумя базовыми объектами: Data Access Object (DAO) и Data Transfer Object (DTO). Классы DAO определяют поведение системы, доступ к данным, находящимся как в хранилище, так и в кешах данных и сессий. DTO определяет состояние, то есть аналогично, например, представлениям (View) в традиционных реляционных моделях. Комбинированное использование DAO/DTO позволяет формировать управляющие классы для использования во время выполнения, в том числе возможно изменение методики распределения данных, правил доступа и иных настроек непосредственно во время функционирования приложения. Для проведения настроек на основе API разработчик может воспользоваться одним из трех режимов: визуальным, программным, импортом собственного класса. Классы, сформированные в визуальном редакторе, могут быть преобразованы в код Java или непосредственно в файл типа .class. Изменения в коде, выполняемые непосредственно во время выполнения, производятся классом ClassLoader и обычно используются для управления распределением данных и пользовательских сессий, а также для мониторинга состояния веб-кластера. Конечно, такой подход несет определенный риск, но в то же время обеспечивает большую гибкость при управлении системами в режиме пиковых нагрузок как по объему данных, так и по количеству пользователей.
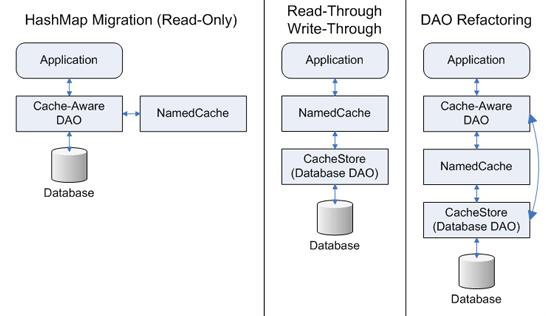 |
| Рис. 2. Схема работы |
Отдельно остановимся на API управления доменами данных (рис. 2) — NamedCache API, который предназначен для программного перераспределения данных в кеше. Способ распределения данных устанавливается XML-документом read/get-mapping-cache и может изменяться программно. Приведем пример программного управления кешем. Рассмотрим стандартную ситуацию заказа в интернет-магазине, в которой нам необходимо оперировать сущностями «заказчик», «заказ», «детали заказа»:
public class Order implements Serializable
{
// определяем статический метод поиска заказа
public static Order getOrder(OrderId orderId)
{
return (Order)m_cacheOrders.get(orderId);
}
// методы обновления атрибутов заказа
// «ленивый» способ обновления подразумевает поиск требуемого атрибута в ближайшем кеше
public Customer getCustomer()
{
return (Customer)m_cacheCustomers.get(m_customerId);
}
// «ленивый» метод загрузки коллекций атрибутов действует по тому же принципу, что и одноименный метод поиска
public Collection getLineItems()
{
return ((Map)m_cacheLineItems.getAll(m_lineItemIds)).values();
}
// поля состояния заказа
private CustomerId m_customerId;
private Collection m_lineItemIds;
// обеспечение связей со связанными данными в кеше
private static final NamedCache m_cacheCustomers = CacheFactory.getCache("customers");
private static final NamedCache m_cacheOrders = CacheFactory.getCache("orders");
private static final NamedCache m_cacheLineItems = CacheFactory.getCache("orderlineitems");
}
API логического уровня включает интерфейсы к объектам управления транзакциями и шаблонами (patterns). Управление транзакциями осуществляется через адаптеры Java-to-Coherence Adaptors (J2CA) к J2EE-контейнерам. Шаблоны используются для следующих основных видов операций: с базами данных, сервисами (например, веб-сервисы, invocation) и финансами (например, поддержка транзакций с электронными счетами, корзиной заказа и т. п.). Рассмотрим класс CacheFactory объекта NamedCache. Его методы:
public void execute(Invocable task, Set setMembers, InvocationObserver observer);
public Map query(Invocable task, Set setMembers);
Они являются базовыми для сервиса инвокации, обеспечивающего распределенные вычисления в системе между нодами кластера в синхронном и асинхронном режимах.
Пример использования
В заключение рассмотрим небольшой пример использования Coherence совместно с популярным веб-сервером BEA WebLogic. Coherence инсталлируется непосредственно поверх WebLogic Portal и интегрируется в его рабочее окружение. Управление пользовательскими сессиями после этого производится средствами Coherence. В результате обеспечивается единообразное программное управление кешем пользовательских сессий, что позволяет повысить нагрузочную способность решения.
Ссылки по теме
- Сайт разработчика
- Применение Coherence на сервере BEA WebLogic
Статья получена: hostinfo.ru









 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить



