 |
Если вы разрабатываете серьезное интернет-приложение или корпоративную систему, скорее всего, вы будет иметь дело с XML. За последнее время это самая популярная технология, и вы просто должны были слышать о ней, поэтому не будем останавливаться на самой концепции XML, а сразу перейдем к сути. При создании скриптов на РНР неоднократно приходится сталкиваться с необходимостью работы с данными в XML-формате, причем очень часто эта работа совершенно тривиальна. Чтение данных, простая выборка (какого-то конкретного узла или значения), изменение данных – все эти функции, с одной стороны, очень просты при описании, но достаточно сложны, когда приходится заниматься этим в реальности.
DOM XML – мощный и сложный инструмент для работы с XMLВ РНР, начиная с версий 4.х, для программистов всегда доступны несколько расширений, которые позволяют произвольно манипулировать XML-данными.
Например, в версии 4.3.х присутствует расширение DOM XML, используя которое можно преобразовать XML в объектную модель и работать с ней согласно спецификации DOM. Иерархия тегов в таком случае будет транслирована в набор объектов РНР, с которыми можно работать через встроенные функции. На низком уровне это расширение использует популярный XML-парсер libxml, взятый из другого OpenSource-проекта – GNOME. Хотя сам формат XML достаточно простой, но вот работа с ним на программном уровне гораздо сложнее – DOM XML в РНР представляет в распоряжение программиста очень много функций, переменных и флагов, так что разбираться со всем этим приходится не один день.
XMLParser использует expatАльтернативой DOM XML может быть применение расширения XMLParser, работающего на основе парсера expat, разработанного Джимом Кларком (James Clark). Работа через XMLParser намного проще и открывает перед разработчиком широкие возможности. Хотя если вам надо не только просто разбирать XML, но и проверять их на соответствие стандарту или определенной схеме данных, тут уже придется использовать другие расширения.
Кроме этих стандартных расширений, на сайте PHP Classes можно найти огромное количество отдельных классов для решения частных задач, связанных с обработкой и проверкой XML, – например, DOMIT XML parser, SAXY XML parser и другие.
Но что же делать, если надо производить какие-то простые действия над XML, когда не надо привлекать на помощь огромные интерфейсы и сложнейшие библиотеки? Для таких случаев в РНР 5.0 появился новый модуль, значительно упрощающий жизнь разработчика. Название его говорит само за себя – SimpleXML.
Если вы работаете с РНР версии 5.0 или выше, то поддержка SimpleXML у вас включена по умолчанию, если это не так, используйте опцию конфигурации --enable-simplexml (или --disable-simplexml для отключения).
Для начала работы необходимо загрузить XML-данные. Это может быть как файл, так и просто строковая переменная, содержащая XML-код. Если вы используете параллельно и DOM XML, то можете сразу загрузить DOM-модель документа в SimpleXML (и потом выгрузить ее обратно для продолжения работы).
Давайте рассмотрим работу с SimpleXML на реальном примере, который позволит продемонстрировать некоторые особенности и нюансы работы расширения. Воспользуемся реальным XML-кодом, частью XML-RPC-ответа поискового сервера Yandex (/redir.php?url=xml.yandex.ru%29%2C в котором содержатся описания найденных в ответ на запрос документов. Вот пример XML-кода, который описывает один документ (результат поиска):
 |
Загрузить этот документ можно функцией. Если документ представлен в виде файла, то код будет иметь вид $res = simplexml_load_file($xml);. Если же у вас есть структура DOM, то ее можно использовать так: $res = simplexml_import_dom($dom);.
SimpleXML необходим корректный заголовок XML-документаА теперь сразу расскажу про одну особенность этого кода. В примерах на php.net встречается фрагмент, когда обычный XML-код загружается в SimpleXML. Имеется в виду, что это может быть не код, строго оформленный по спецификации XML, а только сама структура, например $xml = "<books><book><title>blah</title></book></books>";. Это верно, SimpleXML обработает такой код и представит его в верном иерархическом виде (в виде набора объектов и массивов). А вот с нашим XML в примере будут проблемы. Причина простая – если в вашем XML есть национальные символы, к примеру кириллица, то всегда необходимо указывать корректный XML-заголовок для правильной работы SimpleXML (то есть должно присутствовать <?xml version="1.0" encoding="windows-1251" standalone="yes"?>). Даже если вы получили этот код путем разбора другого кода (а представленный код – это всего лишь фрагмент большого файла), вам придется вручную добавлять заголовок перед загрузкой в SimpleXML. Особенность вторая – независимо от того, какую кодировку вы укажете (в нашем случае это windows-1251), после разбора SimpleXML выдает результат все равно в кодировке UTF-8. Если же вы не укажете заголовок документа или укажете неверную кодировку – SimpleXML откажется разбирать код и вернет ошибку (функции вернут значение FALSE).
Хорошо, документ загружен и преобразован в доступную для работы форму. Но как конкретно SimpleXML его обрабатывает? Все части XML-кода (узлы, или Nodes) преобразовываются в экземпляры класса SimpleXMLElement, а внутри этого объекта список дочерних узлов и атрибутов представлен в виде обычного массива. Если дочерний элемент не содержит вложенных элементов, а содержит только значение, то он представлен в виде массива, доступного как по номеру, так и по названию тега, а если он содержит, в свою очередь, еще элементы, то это будет новый экземпляр класса SimpleXMLElement. Лучше всего воспользоваться для исследования структуры функцией var_dump(), которая в удобной форме покажет структуру данных, возвращаемую любой функцией расширения SimpleXML.
На рисунке ниже показана структура, созданная после загрузки нашего примера. Основной элемент, класс SimpleXMLElement, содержит массив, первый элемент которого – обычная строка, содержащая тег <doccount>1</doccount>, а дальше вторым элементом массива идет снова класс SimpleXMLElement, так как следующий в иерархии узел XML содержит в качестве значения дочерние узлы и должен представляться как самостоятельный объект.
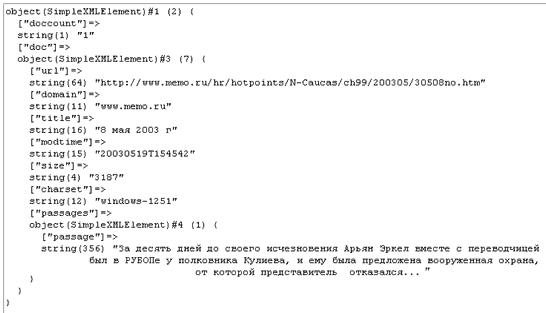 |
Теперь о практическом применении полученной информации. Как получить доступ к информации, хранимой в XML-структуре? Очень просто. Доступ к отдельным элементам и их значениям можно получить, указывая на конкретный элемент (ведь это всего лишь обычный массив). Например, URL документа можно получить так:
$xml_node = $res->doc;
echo $xml_node->url[0];
или без создания отдельного объекта, напрямую адресуясь к нужному элементу:
echo $res->doc->url[0];
или так:
echo $res->doc->url;
Для перебора всех дочерних элементов можно в цикле получить доступ к каждому дочернему узлу и производить над ними нужные операции. Именно так в моем коде обрабатывается ответ сервера «Яндекс» – в цикле я получаю необходимый узел и уже его использую для извлечения данных.
foreach ($xml as $simple_node)
{
echo "URL документа: " . $simple_node->url[0];
}
Кроме доступа к отдельным узлам и получения их значения вы можете получить сразу весь XML-код узла либо всех дочерних элементов. Для этого SimpleXMLElement имеет функцию asXML(), которая возвращает строку с XML-кодом. Пример:
echo $xml->asXML(); // возвращает строку с содержимым XML-документа
echo $xml->doc->asXML(); // возвращает строку с содержимым узла <doc>
Но обратите внимание, что конструкция $xml->asXML(); возвращает только тело XML-документа, без заголовка.
Для отбора узлов можно использовать выражения XPathНе думайте, что простота SimpleXML означает примитивность. Поддерживаются и более мощные возможности, к примеру адресация элементов с помощью специального языка XPath. XPath – это специальный язык (метод) для адресации частей XML-документов и построения ссылок на конкретные узлы или элементы в иерархии XML. Сама по себе спецификация XPath достаточно сложная, но нам пока пригодятся самые базовые сведения. Функция xpath() принимает выражение для отбора узлов и возвращает массив элементов SimpleXMLElement (или один элемент, если в результате был найден только один узел, удовлетворяющий запросу). После вызова этой функции вы можете продолжить работу стандартными средствами SimpleXML. Особенно XPath удобен для навигации по большим документам, когда заранее неизвестно точно, как получить доступ к нужному элементу, да и длинная цепочка указателей на объекты выглядит нечитабельной и сложной к дальнейшей расширяемости.
Например, URL можно найти, применив для отбора следующий код:
$xml_node = $res->xpath("/group/doc/url");
Выражение XPath /group/doc/url указывает на путь по структуре документа к нужному элементу. Результатом работы будет массив, содержащий один элемент SimpleXMLElement, который, в свою очередь, и содержит значение указанного нами узла. С помощью XPath можно строить очень сложные выражения, программист таким образом получает в свои руки мощнейший и удобный инструмент для отбора узлов по любому правилу.
 |
Для получения любого дочернего узла в виде массива можно воспользоваться функцией children(). Она возвращает SimpleXMLElement, который содержит один элемент – первый дочерний элемент, если не указан точный номер, или же тот элемент, номер которого указан. Пример:
$xml_node = $res->doc->children();
echo $xml_node[0]; // выводит URL, первый (с индексом 0) элемент
echo $xml_node[5]; // выводит кодировку, шестой дочерний элемент узла <doc>
В заключение расскажем еще про изменение значений элементов. Сделать это так же просто, как и прочитать соответствующее значение. Сначала необходимо найти нужный элемент, а потом просто присвоить ему новое значение:
$xml->doc->url = "/redir.php?url=test.com%2F"; // меняет URL в документе на новый
Но необходимо быть внимательным. Если в примере узел <url> исходного документа содержал строку, то все нормально. Но если вы присвоите значение узлу, который уже содержит дочерние элементы и представлен в виде SimpleXMLElement, то потеряете все данные этого узла – SimpleXML просто удалит их, а родительский узел будет теперь содержать строковое значение. К примеру, этот код удалит все дочерние элементы узла <doc> и будет содержать обычную строку:
$xml->doc = "это просто строка";
echo var_dump($xml);
echo $xml->asXML();
Тут также вас поджидает некоторая проблема – если вы заменяете какой-либо узел или значение элемента на строку с кириллическими символами, то функция asXML() впоследствии может неверно отображать XML, хотя при просмотре структуры SimpleXMLElement с помощью var_dump() видно, что все значения были присвоены корректно.
 |
Как видно на рисунке, функция asXML() отображает только одну часть содержимого, просто игнорируя остальное, даже закрывающий тег, в то же время в самом SimpleXMLElement все прекрасно уживается. Видимо, это некоторая недоработка в самой библиотеке.
Проводить очень сложную обработку XML-документов при помощи SimpleXML все же сложно, да и серьезные приложения, как правило, требуют более мощных инструментов, например валидацию XML при помощи схем или DTD. Но для простых работ вроде чтения/записи SimpleXML может обеспечить получение доступа к отдельным элементам и их изменение, причем достаточно просто. А поддержка мощного языка адресации XPath позволяет с легкостью манипулировать отдельными частями любого XML-документа.
Ссылки по теме
Статья получена: hostinfo.ru










 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить




