 |
Ситуация, когда на загруженной веб-странице вместо нормального русского текста видны всевозможные «кракозябры», знакома, наверное, каждому интернетчику. Причина ее возникновения — путаница с различными существующими кодировками. Это проблема достаточно серьезна. Конечно, подавляющее большинство веб-страниц отображается абсолютно нормально. Тем не менее встречаются сайты, на которых невозможно прочесть ни одного русского слова.
Поэтому давайте, чтобы не попадать впросак, попробуем разобраться с этим вопросом раз и навсегда.
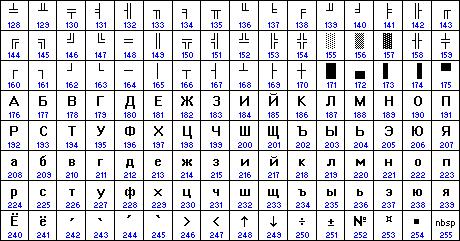
Для начала, наверное, нужно вообще разобраться, что же такое кодировка. Под этим термином понимают специальную таблицу, в которой перечислены все возможные значения одного байта (всего их 256) и символы, соответствующие каждой цифре. Фактически, текстовая информация (как и любая другая) поступает с веб-сервера на компьютер пользователя в цифровом виде (последовательность байтов). При этом каждый символ — это число от 0 до 255. Браузер сверяется со специальной таблицей и выводит на экран не цифры, а соответствующие им буквы. Таким образом, пользователь видит перед собой нормальный текст.
Первые 128 символов стандартизированы. Они одинаковы абсолютно во всех кодировках по всему миру. Если говорить о символах, то это весь английский алфавит, цифры и основные знаки. Оставшиеся 128 позиций отданы «на откуп» национальным алфавитам и дополнительным символам. В подавляющем большинстве стран именно так все и есть. Однако в России существует не одна и даже не две национальные кодировки. Их ровно пять. Таким образом, если текст написан по-русски в одной кодировке, то в другой он будет выглядеть абсолютно беспорядочным набором разных знаков.
Многие читатели наверняка спросят: "Но почему в России так много разных кодировок?". Для ответа на этот вопрос придется совершить небольшой экскурс в историю. Все началось в 70-х годах прошлого века. Именно тогда на наших компьютерах (не персональных — их тогда еще не было) появилась операционная система UNIX. Естественно, ее адаптировали к русскому языку. Именно тогда и возникла первая кодировка, получившая название KOI-8. С тех пор она стала стандартом "де-факто" для всех UNIX-подобных операционных систем — например для Linux.
 |
Немного позже началось победное шествие персональных компьютеров. А вместе с ними огромное распространение получила операционная система MS-DOS. Ее разработчик, компания Microsoft, во время русификации не воспользовалась KOI-8, а придумала свою кодировку, получившую название DOS (кодовая страница 866). В этой таблице среди дополнительных символов появились элементы рамок, которые значительно облегчали рисование таблиц в различных текстовых редакторах. Это тоже способствовало распространению кодировки DOS. Кстати, примерно в то же время или немного позже на российский рынок вышли компьютеры Macintosh. Естественно, при русификации установленной на них операционной системы была создана еще одна таблица символов — MAC. Правда, нужно отметить, что она практически никогда не использовалась вследствие малого распространения самих «Макинтошей».
В 1990 году компания Microsoft выпустила новую операционную версию Windows 3.0. В ней поддержка национальных языков была встроена. Но вот что интересно — по каким-то причинам специалисты Microsoft не воспользовались уже существующей русской кодировкой DOS, а снова изобрели новую — Win (кодовая страница 1251). Скорее всего, это было сделано из-за введения в таблицу других дополнительных символов вместо рамок и тому подобных символов. Но достоверно о причинах появления кодировки Win мы, скорее всего, уже не узнаем.
Еще позже на проблему наличия нескольких национальных кодировок в России и некоторых других странах обратила внимание международная организация International Organization for Standardization, занимающаяся вопросами стандартизации. И опять же, вместо того чтобы за основу взять наиболее распространенную кодировку (на тот момент это была таблица Win), представители ISO выдумали свою (ISO 8859-5). Но практического применения она не получила. И хотя поддержка кодировки ISO есть во всех браузерах, наверное, не существует ни одного сайта, ее использующего.
 |
Кроме того, уже достаточно долгое время наблюдаются попытки «проталкивания» универсальной кодировки Unicode. Ее создатели предложили использовать на каждый символ не один, а два байта. Это позволяет увеличивать число возможных значений до 65535 и вместить в таблицу все символы существующих алфавитов. Правда, все эти попытки остаются абсолютно бесплодными.
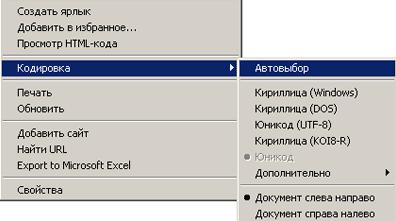
А теперь, когда мы разобрались с разными кодировками, давайте рассмотрим, почему с ними возникают проблемы. Когда на экране вместо нормальной веб-страницы отображаются «кракозябры», это значит, что сервер и браузер не смогли «договориться» между собой — первый отправляет текст в одной кодировке, а второй — выводит его в другой. Естественно, при правильной настройке веб-сервера такого не происходит. Он просто указывает, в какой кодировке высылается текст. Браузер «понимает» это и настраивается соответствующим образом. Так все выглядит в идеале. Кроме того, для этого пользователь должен включить режим автовыбора кодировки в своем браузере. Если же он этого не сделал, то веб-страница будет всегда отображаться в соответствии с установленной в настройках таблицей. А что, если сервер отправит страницу в кодировке KOI-8, а браузер настроен на Win? В этом случае на экране вместо русского текста будет отображен беспорядочный набор символов. Но справиться с этим легко. Достаточно переключить браузер в нужную кодировку или установить режим автовыбора, чтобы страничка была отображена нормально.
Другая причина появления на экране «крякозябр» — неправильная настройка сервера. В этом случае он указывает браузеру одну кодировку, но на самом деле отправляет текст в другой. Здесь пользователю уже не поможет режим автовыбора. Но зато он может просто-напросто подобрать нужную кодировку, перепробовав поочередно все возможные. Учитывая то, что реально используются всего две таблицы символов, никаких сложностей эта процедура не вызовет.
 |
Гораздо хуже, когда незнающие веб-мастера пытаются решить проблему с кодировками с помощью специального мета-тега charset, предназначенного для явного указания используемой на данной странице таблицы символов. Дело в том, что этот тег имеет приоритет перед указаниями веб-сервера. А поэтому браузеру указывается, что для отображения текста нужно использовать кодировку, заданную в charset. На первый взгляд, никаких проблем тут возникнуть не должно. Но на самом деле... На самом деле, сейчас все большее распространение получают серверы, определяющие кодировку запроса браузера и автоматически преобразовывающие текст в соответствии с этой таблицей. Что же получается? Сервер действительно перекодирует веб-страничку в соответствии с настройками браузера пользователя. Но он не может изменить значение мета-тегов. Таким образом, браузер получает указание, что отображать текст нужно с использованием таблицы, явно заданной веб-мастером, но получает его в другой кодировке. А поскольку мета-теги имеют приоритет даже над установками браузера, то пользователь лишается всякой возможности прочитать информацию.
Итак, как мы видим, в случае грамотной настройки сервера и отсутствии на веб-странице мета-тега charset русский текст будет отображаться корректно в подавляющем большинстве случаев. И вообще, согласно различным исследованиям, порядка 95-98% всех сайтов в Рунете написаны с использованием кодировки Win. Соответственно, многие посетители Сети даже не пользуются режимом автовыбора таблицы символов. Ведь вполне достаточно просто установить кодировку Win, чтобы без всяких проблем просмотреть подавляющее большинство сайтов. Поэтому начинающим веб-мастерам также стоит использовать эту таблицу символов при создании страниц, но не задавать ее явно с использованием мета-тегов.
Ссылки по теме
Статья получена: hostinfo.ru










 Противовирусные препараты: за и против
Противовирусные препараты: за и против Добро пожаловать в Армению. Знакомство с Арменией
Добро пожаловать в Армению. Знакомство с Арменией Крыша из сэндвич панелей для индивидуального строительства
Крыша из сэндвич панелей для индивидуального строительства Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан
Возможно ли отменить договор купли-продажи квартиры, если он был уже подписан Как выбрать блеск для губ
Как выбрать блеск для губ Чего боятся мужчины
Чего боятся мужчины Как побороть страх перед неизвестностью
Как побороть страх перед неизвестностью Газон на участке своими руками
Газон на участке своими руками Как правильно стирать шторы
Как правильно стирать шторы Как просто бросить курить
Как просто бросить курить

